
Regex and pattern matching
Welcome to part 6 of the workshop. As usual, to keep each article as compact as possible, I will shortcut the queries to snippets. If you want to see the complete code, please consult my GitHub page for this workshop. If Google brought you here, you might check also the start of the series, or the whole series.
In this workshop, I will show you some practical examples of regexes and different ways to use them. The official documentation has a few examples, but I think there is more to cover and we should dive in deeper. If you want to know about pattern flags (like match case insensitive), it is covered on the official docs. As always: let’s jump right in!
Preparation
Before we continue, you need to make sure, that your cluster can run regexes. If the following query returns limited or false, you will not be able to run the workshop properly:
GET _cluster/settings?include_defaults&filter_path=defaults.script.painless.regexYou enable regex by adding the following parameter elasticsearch.yml on every node in the cluster. The cluster needs a restart:
script.painless.regex.enabled: true
Data
As usual, we will use a small document as data from a small, fictional software company:
PUT companies/_doc/1
{ "ticker_symbol" : "ESTC",
"market_cap" : "8B",
"share_price" : 85.41}The field „market_cap“ is comfortable to read but bad for calculations. With regexes, we will convert this field to a value of long datatype.
Regexes
The regex implementation in Painless is the same as in Java. If you want to know how to specify character classes or how to define a quantifier inside the „/ /“, please ĥave a look at the oracle documentation.
The following example matches the „8B“ of the „Market_cap“ field:
if ( doc['market_cap.keyword'].value =~ /B$/){...}The „=~“ matches substrings, t’s called the find operator. While the „==~“ needs to match the whole string, it’s called the match operator. If we want to use the match operator, the regex would be:
if ( doc['market_cap.keyword'].value ==~ /^8B$/){...}The Java Matcher Class
The Java Matcher Class provides everything you need for pattern matching. While finding patterns works great, I found out that grouping the matches is somehow broken in Painless. I have seen this bug in all 7.x.x and now also in 8.0.0 Elasticsearch versions. I can demonstrate this – let’s define a pattern that splits the string „8B“ into 2 groups: group 1 is „8“ and group 2 is „B“. We define first the pattern:
Pattern p = /([0-9]+)([A-Za-z]+)$/;Now we call from our Pattern object (p) the matcher class and want to know if the pattern has matched:
def result = p.matcher(market_cap_string).matches();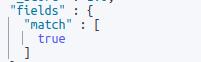
So, that works, we have a confirmed match. I try now the group() method because with that method I could store the first group in a variable. Let’s see what happens:
def result = p.matcher(market_cap_string).group(1);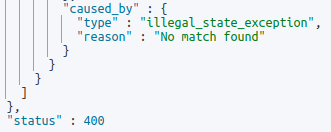
You might think I have done something wrong – so did I. I have spent hours researching this, and I have even reported it to Elasticsearch. So far no response – if you know what’s wrong here, please feel free to send me a pm via LinkedIn or update the post. Thanks in advance!
But there are workarounds. Let me first show you the replaceAll() method from the same class. To get this working, we need to match the substring and modify our pattern, then we replace „B“ with nothing, or in other words, we remove „B“:
Pattern p = /([A-Za-z]+)$/;
def result = p.matcher(market_cap_string).replaceAll('');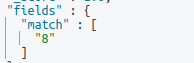
Now, we can also use the previous pattern with 2 groups that match the whole string and replace the whole string with the first group, which also remove „B“ from „8B“:
Pattern p = /([0-9]+)([A-Za-z]+)$/;
def market_cap = p.matcher(market_cap_string).replaceAll('$1');Matcher Class examples
On my GitHub page are plenty of examples for the matcher class. There are examples for pipelines, stored scripts, scripted fields, and more. Please have a look if you’re stuck.
The Java String contains() Method
There is another way, that works in every context: use the contains() method, which comes with every String object. Let’s have a look:
if (market_cap_string.contains("B")){
mc_long_as_string = market_cap_string.replace('B', '');As you can see, String objects have more methods. The replace() method transforms now „8B“ to „8“. Which is still a string. So let’s call the static method parseInt() from the Integer Class and transform „8“ to a long datatype:
if (market_cap_string.contains("B")){
mc_long_as_string = market_cap_string.replace('B', '');
mc_long = (long) Integer.parseInt(mc_long_as_string);
market_cap = mc_long * 1000000000
}
Now, what I am missing is some positional matching. With the Java Pattern Class, I was able to define where the „B“s should be for a match: at the end of the string. WIth contains() the string can be anywhere, But the String Class provides me a handy method for a match at the end of the line: endsWith(). Of course, there is also a method startsWith(). But back to the example:
if (market_cap_string.endsWith("B")){...}Grok and dissect patterns
There is one more thing: grok and dissect patterns. If you are familiar with Logstash, this might be interesting for you. Since only Grok uses regex patterns (dissect does not use regex, but is faster), I will skip dissect for the example and focus on grok.
However: unfortunately only runtime mappings have implemented the grok and dissect plugin. Therefore it’s not universally usable like the String methods or the Pattern/Matcher Classes.
Let’s have a look at how we could split the string „8B“ and store „8“ and „B“ in two variables:
String mc_long_as_string =
grok('%{NUMBER:markcap}').extract
(doc['market_cap.keyword'].value).markcap;
String factor_as_string =
grok('(?<fact>[A-Z])').extract
(doc['market_cap.keyword'].value).fact;Grok is built on a Syntax (the name of the pattern), in this case, NUMBER since we want the numbers extracted from the string – and Semantic (the name of the identifier), in this case, „markcap„. It extracts the pattern from the document (or the string) and saves it in the object markcap. Grok and dissect will be a topic in the Logstash workshop
My hope for the future is, that Elasticsearch implements grok and dissect patterns also in other contexts. But for now, we are limited to runtime mappings.
Conclusion
If you made it here: Congratulations! You should now be able to match patterns with regex, String methods, or grok patterns.
If you have questions, leave a comment, connect or follow me on LinkedIn